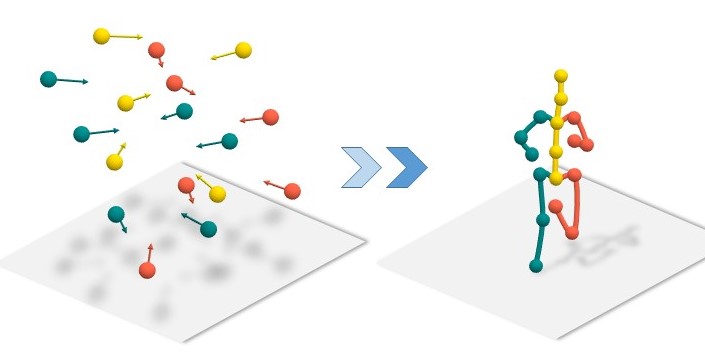
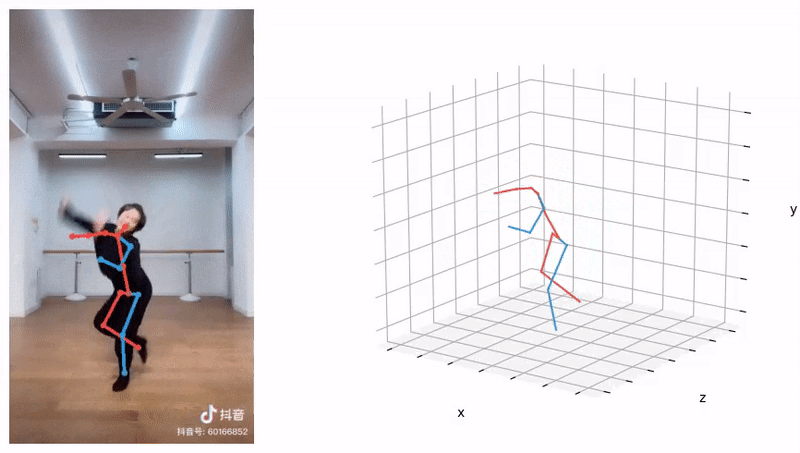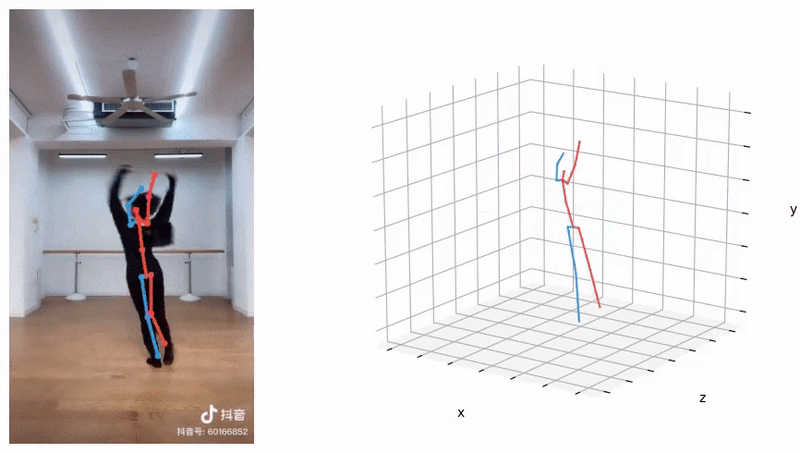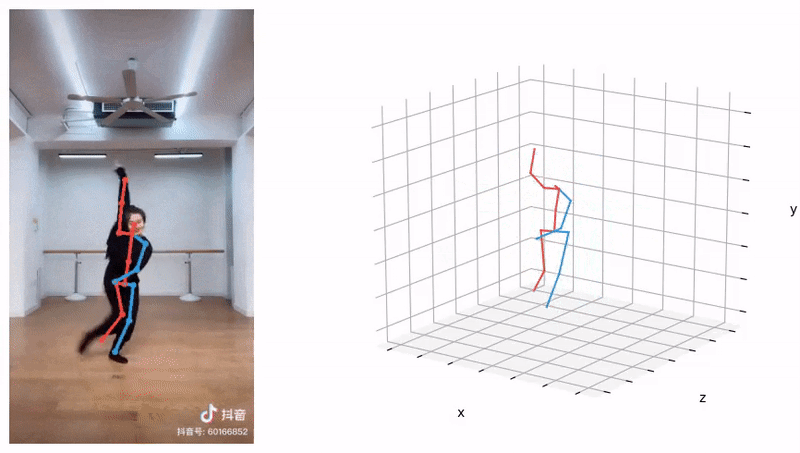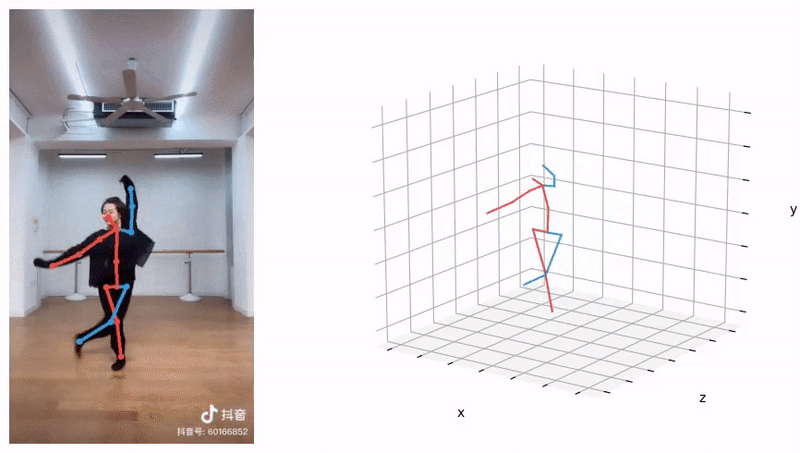
Learning 3D human pose prior is essential to human-centered AI.
Here, we present GFPose, a versatile framework to model plausible 3D human poses for various applications.
At the core of GFPose is a time-dependent score network, which estimates the gradient on each body joint and progressively denoises
the perturbed 3D human pose to match a given task specification. During the denoising process, GFPose implicitly incorporates pose priors
in gradients and unifies various discriminative and generative tasks in an elegant framework.
Despite the simplicity, GFPose demonstrates great potential in several downstream tasks.
Our experiments empirically show that 1) as a multi-hypothesis pose estimator, GFPose outperforms existing SOTAs by 20% on Human3.6M dataset.
2) as a single-hypothesis pose estimator, GFPose achieves comparable results to deterministic SOTAs, even with a vanilla backbone.
3) GFPose is able to produce diverse and realistic samples in pose denoising, completion and generation tasks.
@article{ci2022gfpose,title={GFPose: Learning 3D Human Pose Prior with Gradient Fields},author={Ci, Hai and Wu, Mingdong and Zhu, Wentao and Ma, Xiaoxuan and Dong, Hao and Zhong, Fangwei and Wang, Yizhou},journal={arXiv preprint arXiv:2212.08641},year={2023},}
ICLR
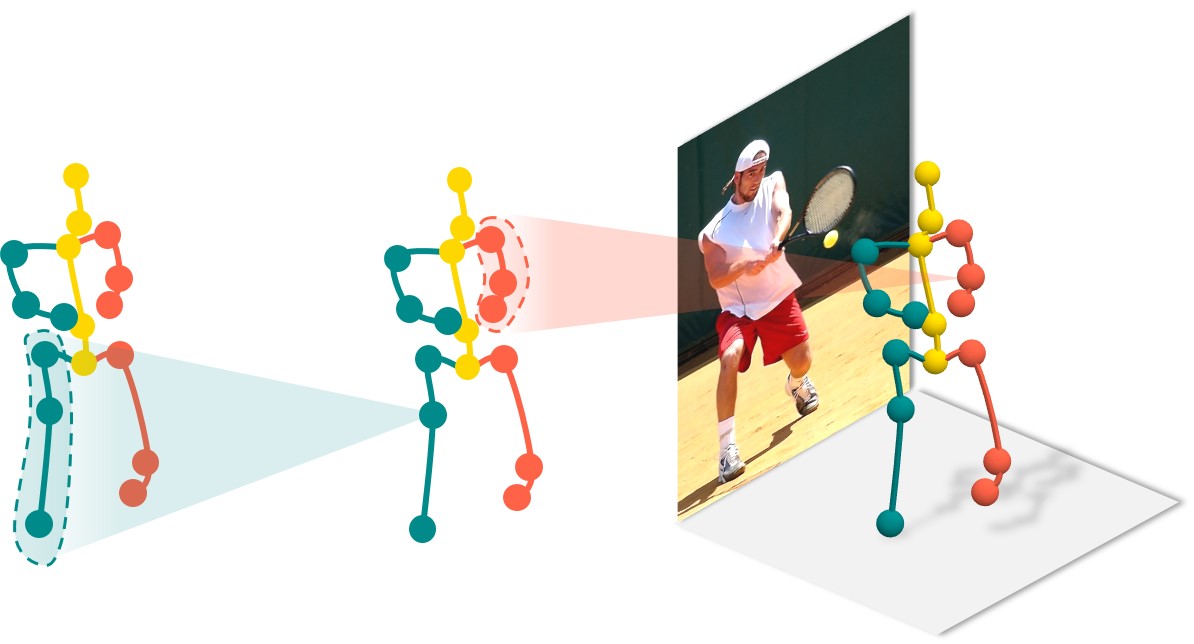
Proactive Multi-Camera Collaboration for 3D Human Pose Estimation
For human motion capture (MoCap), particularly outdoors, the fixed-viewpoint
multi-camera solutions are susceptible to dynamic occlusions and constrained in
capture space. While an active camera approach aims to proactively control the camera poses to find optimal viewpoints for 3D reconstruction. This work introduces a
multi-agent reinforcement learning (MARL) scheme to proactive Multi-Camera
Collaboration for 3D Human Pose Estimation (MCC-HPE) in dynamic human
crowds. At its core is a novel Collaborative Triangulation Contribution Reward
(CTCR) that incentivizes agents according to their weighted average marginal contribution to the 3D reconstruction. CTCR improves convergence and alleviates the
multi-agent credit assignment issue resulted from using 3D reconstruction accuracy
as the shared reward. To better capture environment dynamics and to encourage
anticipatory behaviors for occlusion avoidance, we jointly train our model with
multiple world dynamics learning tasks. We evaluate our proposed method in
four photo-realistic UE4 environments to ensure validity and generalizability. The
empirical results show that our methods steadily outperform the fixed and active
baselines in different scenarios with various numbers of cameras and humans.
@inproceedings{ci2023active,title={Proactive Multi-Camera Collaboration for 3D Human Pose Estimation},author={Ci*, Hai and Liu*, Mickel and Pan*, Xuehai and Zhong, Fangwei and Wang, Yizhou},booktitle={ICLR},year={2023},}
2021
CVPR
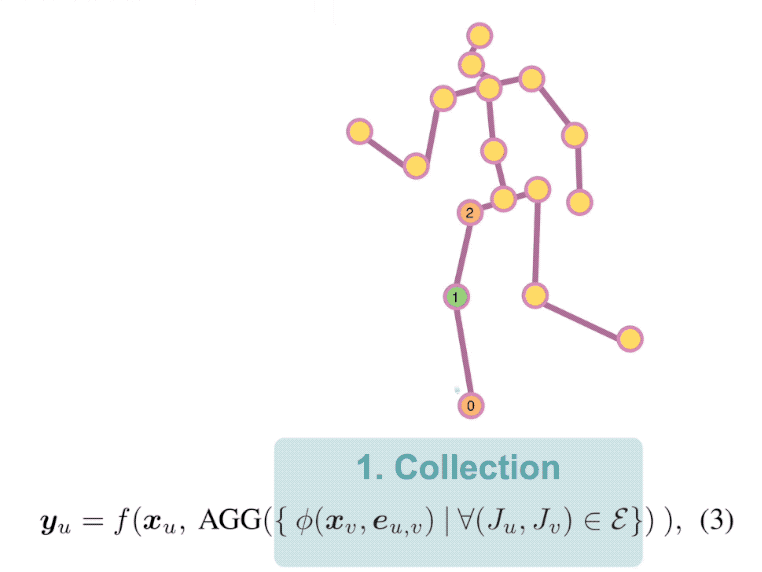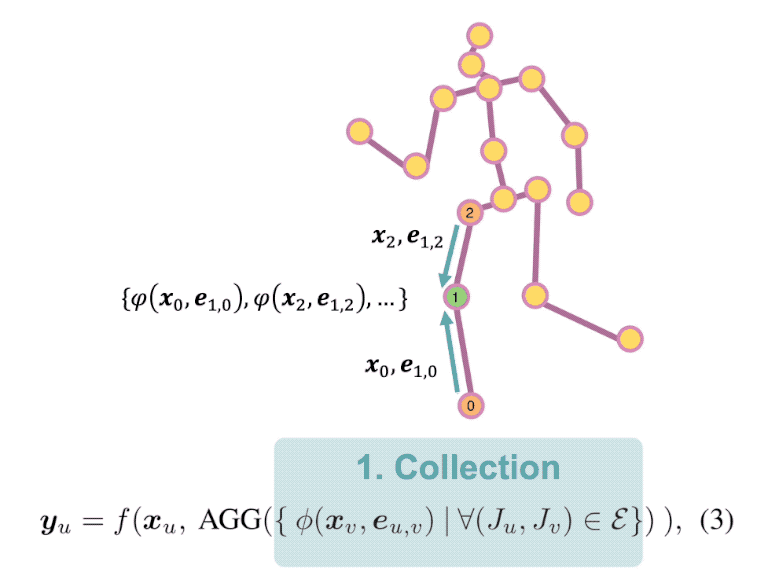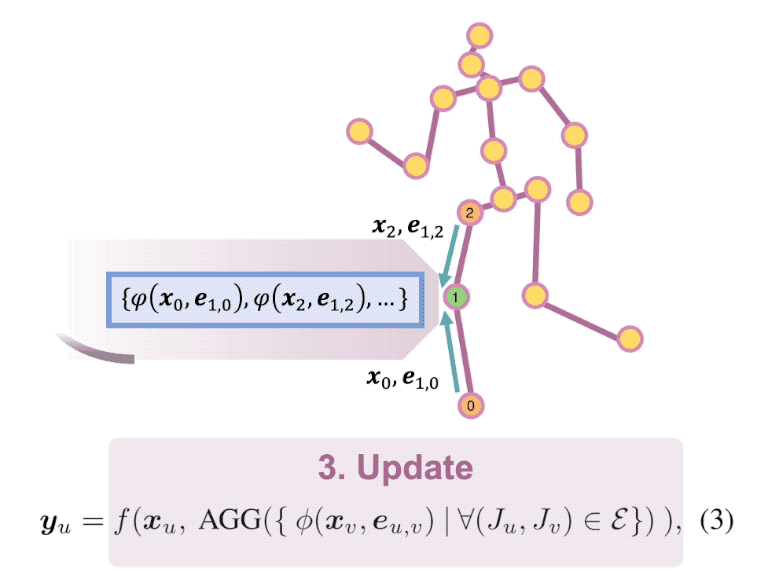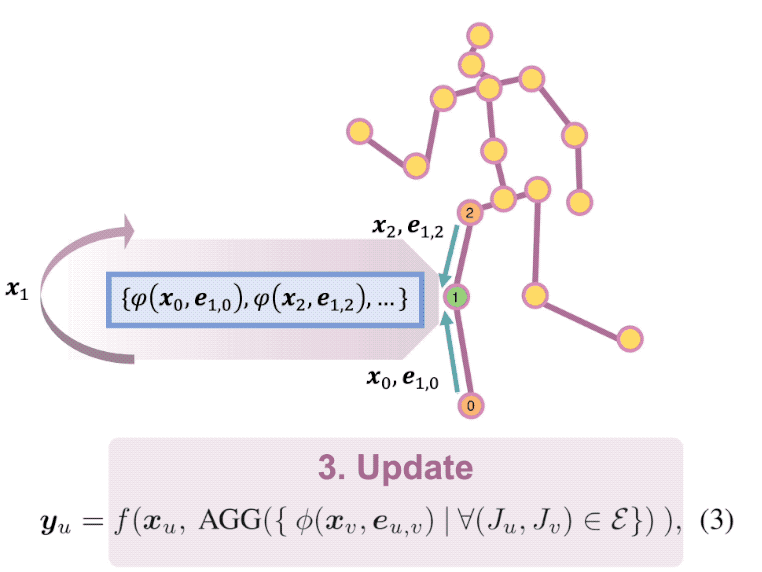
Context Modeling in 3D Human Pose Estimation: A Unified Perspective
Estimating 3D human pose from a single image suffers
from severe ambiguity since multiple 3D joint configurations
may have the same 2D projection. The state-of-the-art meth-
ods often rely on context modeling methods such as pictorial
structure model (PSM) or graph neural network (GNN) to
reduce ambiguity. However, there is no study that rigorously
compares them side by side. So we first present a general for-
mula for context modeling in which both PSM and GNN are
its special cases. By comparing the two methods, we found
that the end-to-end training scheme in GNN and the limb
length constraints in PSM are two complementary factors to
improve results. To combine their advantages, we propose
ContextPose based on attention mechanism that allows en-
forcing soft limb length constraints in a deep network. The
approach effectively reduces the chance of getting absurd
3D pose estimates with incorrect limb lengths and achieves
state-of-the-art results on two benchmark datasets. More
importantly, the introduction of limb length constraints into
deep networks enables the approach to achieve much better
generalization performance.
@inproceedings{ma2021context,title={Context Modeling in 3D Human Pose Estimation: A Unified Perspective},author={Ma*, Xiaoxuan and Su*, Jiajun and Wang, Chunyu and Ci, Hai and Wang, Yizhou},booktitle={CVPR},pages={6238--6247},year={2021},}
2020
TPAMI
Locally Connected Network for Monocular 3D Human Pose Estimation
We present an approach for 3D human pose estimation from monocular images. The approach consists of two steps: it first
estimates a 2D pose from an image and then estimates the corresponding 3D pose. This paper focuses on the second step. Graph
convolutional network (GCN) has recently become the de facto standard for human pose related tasks such as action recognition.
However, in this work, we show that GCN has critical limitations when it is used for 3D pose estimation due to the inherent weight
sharing scheme. The limitations are clearly exposed through a novel reformulation of GCN, in which both GCN and Fully Connected
Network (FCN) are its special cases. In addition, on top of the formulation, we present locally connected network (LCN) to overcome the
limitations of GCN by allocating dedicated rather than shared filters for different joints. We jointly train the LCN network with a 2D pose
estimator such that it can handle inaccurate 2D poses. We evaluate our approach on two benchmark datasets and observe that LCN
outperforms GCN, FCN, and the state-of-the-art methods by a large margin. More importantly, it demonstrates strong
cross-dataset generalization ability because of sparse connections among body joints.
@article{ci2020locally,title={Locally Connected Network for Monocular 3D Human Pose Estimation},author={Ci*, Hai and Ma*, Xiaoxuan and Wang, Chunyu and Wang, Yizhou},journal={TPAMI},year={2020},publisher={IEEE},}
2019
ICCV
Optimizing Network Structure for 3D Human Pose Estimation
A human pose is naturally represented as a graph where
the joints are the nodes and the bones are the edges. So
it is natural to apply Graph Convolutional Network (GCN)
to estimate 3D poses from 2D poses. In this work, we propose
a generic formulation where both GCN and Fully Connected
Network (FCN) are its special cases. From this formulation,
we discover that GCN has limited representation
power when used for estimating 3D poses. We overcome
the limitation by introducing Locally Connected Network
(LCN) which is naturally implemented by this generic formulation.
It notably improves the representation capability
over GCN. In addition, since every joint is only connected
to a few joints in its neighborhood, it has strong generalization
power. The experiments on public datasets show it:
(1) outperforms the state-of-the-arts; (2) is less data hungry
than alternative models; (3) generalizes well to unseen
actions and datasets.
@inproceedings{ci2019optimizing,title={Optimizing Network Structure for 3D Human Pose Estimation},author={Ci, Hai and Wang, Chunyu and Ma, Xiaoxuan and Wang, Yizhou},booktitle={ICCV},pages={2262--2271},year={2019},}
2018
ECCV
Video Object Segmentation by Learning Location-Sensitive Embeddings
We address the problem of video object segmentation which
outputs the masks of a target object throughout a video given only
a bounding box in the first frame. There are two main challenges to
this task. First, the background may contain similar objects as the target.
Second, the appearance of the target object may change drastically
over time. To tackle these challenges, we propose an end-to-end training
network which accomplishes foreground predictions by leveraging the
location-sensitive embeddings which are capable to distinguish the pixels
of similar objects. To deal with appearance changes, for a test video, we
propose a robust model adaptation method which pre-scans the whole
video, generates pseudo foreground/background labels and retrains the
model based on the labels. Our method outperforms the state-of-the-art
methods on the DAVIS and the SegTrack v2 datasets.
@inproceedings{ci2018video,title={Video Object Segmentation by Learning Location-Sensitive Embeddings},author={Ci, Hai and Wang, Chunyu and Wang, Yizhou},booktitle={ECCV},pages={501--516},year={2018},}